
The Sieve of Eratosthenes is a well known old algorithm for finding prime numbers up to a given limit. If you don't know how it works, the short version is that you basically write up every number starting with 2 up to the limit. You then remove all multiples of 2, and the next number in the list (3) is prime. Remove all multiples of 3.. next number (5) is prime.. and so on.
Now imagine modeling the sieve using Communicating Sequential Processes (CSP). Start by creating a seed process, all it does it outputing all the numbers from 2 to n.
For every number x received, create a filtering process - a process which only job is to remove all multiples of x and pass all other values along. Daisy-chain these filtering process for every number you receive, each represents a prime number.

We can model this in clojure (and in go-lang) using go-blocks from core.async.
(ns primesieve.core
(:require [clojure.core.async :as async :refer [go-loop chan >! <! <!! close! filter< to-chan]]))
Start by setting up the namespace, we're going to need a few things from core.async.
(defn gen [upper-limit]
(to-chan (range 2 upper-limit)))
Now create the generating seed process. to-chan is sugar for creating a channel, return the channel and then continue add all items from a collection to the channel. In this case the collection is a lazy sequence of numbers between 2 and upper-limit. It's all run in a microthread (go-block).
(defn sieve-filter [in prime]
(filter< #(pos? (rem % prime)) in))
Next we create a filtering process, filter< is sugar for creating a channel, reading from a incoming channel, and outputing all values that pass a predicate test to the output channel. It's also launched in a go-block.
(defn sieve-builder [in]
(let [out (chan)]
(go-loop [in in]
(if-let [prime (<! in)]
(do (>! out prime)
(recur (sieve-filter in prime)))
(close! out)))
out))
Next we create the function that will daisy-chain filtering blocks, there are no sugar for this, so manually launch a go-block, read a prime number from the input channel, pass this prime along to an output channel, and daisy-chain a new filtering process.
(defn collect [in]
(<!! (async/into [] in)))
To collect all the results, we can use into, which will collect all received values and add them to the datastructure of your choice, a vector in this case.
(defn primes [upper-limit]
(-> (gen upper-limit)
(sieve-builder)
(collect)))
Create a function for generating primes below upper-limit, it will spin up the generator, connect the generator to the sieve-builder, and connect the sieve-builder to the final result collector.
user> (primes 20)
[2 3 5 7 11 13 17 19]
And it works! But.. is it fast? and what level of concurrency is achieved?

Not at all.. it's actually painfully slow, about 30 seconds to find all the primes below 100000. I aborted the run, since I didn't want to wait 5 minutes to complete 10 runs. It isn't really managing to use all cores (HT) properly, in addition to spending most of it's time context switching between the micro-threads. Go-threads are light weight, but there is still some context needed, and each process is doing so little work before blocking - waiting for the next value to be received.
If the processes could do more work before getting blocked and context-switched, maybe it would be faster. Let's try adding a 512 value buffer between them.
(def bufsize 512)
(defn sieve-filter [in prime]
(filter< #(pos? (rem % prime)) in (chan bufsize)))
(defn sieve-builder [in]
(let [out (chan bufsize)]
.......
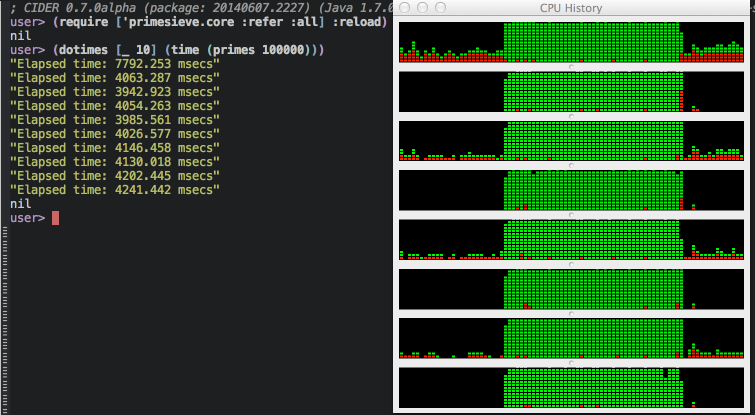
Now, that's better, from 30 seconds to 4 seconds to calculate primes below 100000. Now we get full CPU utilization as well.
But, is it any good? No, not at all! It's actually still pretty terrible, there are so many better and faster ways of doing this. The problem here is that we have a massive overhead because of communication, we're barely doing any computation before shuffling values along to the next guy.
"Also note that async channels are not intended for fine-grained computational parallelism, though you might see examples in that vein."
This is just a fun example, and core.async isn't really intended for this, as quoted above by the original announcement post.
- Top picture is taken by Ryan Prince (cc by-nc-sa 2.0)